Aprendizaje de máquina (Machine learning)
Métodos computacionales para aprender de datos con el fin de replicar una tarea o toma de decisión.
Existen varios paradigmas en aprendizaje de máquina, con distintos objetivos:
- El aprendizaje supervisado procura predecir o estimar una variable respuesta a partir de datos de entrada
- El apprendizaje no supervisado procura describir estructuras interesantes en datos, donde no necesariamente hay una respuesta que predecir
- El aprendizaje semi-supervisado procura utilizar datos asociados a una variable respuesta al mismo tiempo que datos sin la variable para procurar mejor estimarla. Estos es intenta explotar datos sin etiquetas para mejorar la estimación.
- El aprendizaje por refuerzo intenta estimar la mejor política posible en un problema de toma de decisiones secuenciales.
Ejemplos de tareas de aprendizaje:
- Predecir si un individuo va a sobrevivir el hundimiento del Titanic,
- Detectar llamados de murciélagos en grabaciones ultrasónicas,
- Clasificar especies de animales en imágenes digitales producidas a través de foto trampeo,
- Estimar el ingreso mensual de un hogar a partir de las características de la vivienda,
- Dividir a los clientes de Netflix según sus gustos.
- Recomendar artículos a clientes de un programa de lealtad o servicio online.
Ejercicio 1: De los ejemplos anteriores, cuáles consideran que corresponden a aprendizaje supervisado, cuáles a aprendizaje no supervisado y cuáles se podrían resolver con ambos?
Las razones usuales para intentar resolver estos problemas computacionalmente son diversas:
Quisiéramos obtener una respuesta barata, rápida, automatizada, y con suficiente exactitud y precisión. Por ejemplo, reconocer caracteres en una placa de coche de una fotografía se puede hacer por personas, pero eso es lento y costoso.
Show code
knitr::include_graphics("1_license.jpeg")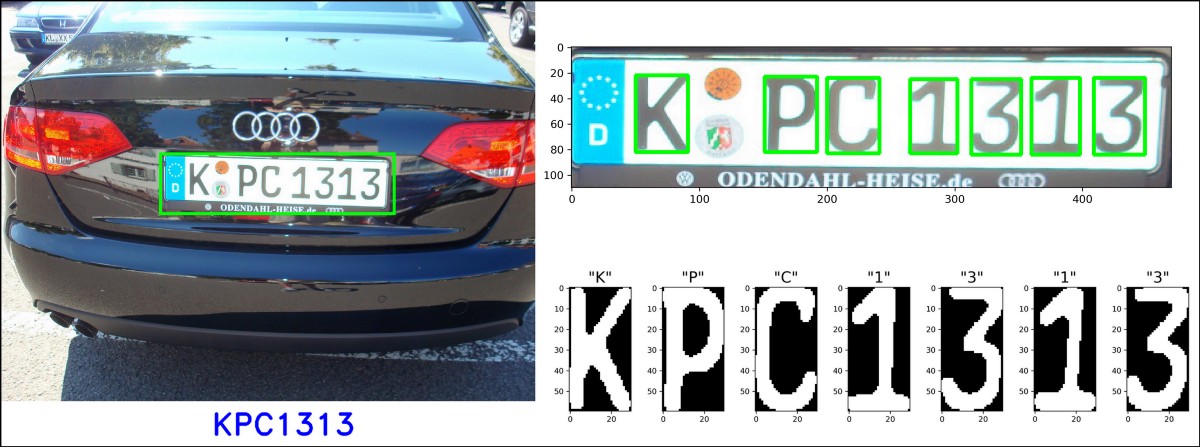
Igual ver cada fotografía para detectar e identificar los animales ahí presentes toma muchísimo tiempo.
Show code
knitr::include_graphics("2_trampa.jpg")
Quisiéramos superar el desempeño actual de los expertos o de reglas simples utilizando datos: por ejemplo, en la decisión de dar o no un préstamo a un solicitante, puede ser posible tomar mejores decisiones con algoritmos que con evaluaciones personales o con reglas simples que toman en cuenta el ingreso mensual, por ejemplo.
¿Lo mismo para la mejor toma de decisiones en cuanto al manejo de recursos naturales?
También es de gran interés entender de manera más completa y sistemática el comportamiento de un fenómeno, identificando variables o patrones importantes.
¿Dado un conjunto de datos ecológicos podemos hacer generar modelos que nos permitan ir explorando distintos aspectos de la integridad ecosistémica para generar conocimiento?
De una vez adelantamos que el acercamiento que se sigue para generar el índice de integridad propuesto es uno de aprendizaje supervisado. Existe una variable que sirve de evidencia para el nivel de condición de los distintos ecosistemas del país y a la par se tienen variables que permiten estimar y, eventualmente, explicar este nivel de condición. El único detalle importante aquí es que la evidencia es categórica, y el índice deseado es uno continuo entre 0 y 1.
El aprendizaje de máquina generalmente se lleva a cabo con ayuda de software especializado. Programas propietarios o de código abierto o comunmente utilizando lenguajes de programación. Por ejemplo R, python y Julia.
Recomendamos ampliamente aprender los tres en la medida de lo posible pues ofrecen distintas posibilidades y ventajas. En esta sesión trabajaremos con R.
Manejo de datos y modelado en R
Para comenzar carguemos unos datos ejemplo al espacio de trabajo de R.
Show code
class : RasterLayer
dimensions : 911, 1185, 1079535 (nrow, ncol, ncell)
resolution : 250, 250 (x, y)
extent : 3697500, 3993750, 908000, 1135750 (xmin, xmax, ymin, ymax)
crs : +proj=lcc +lat_0=12 +lon_0=-102 +lat_1=17.5 +lat_2=29.5 +x_0=2500000 +y_0=0 +datum=WGS84 +units=m +no_defs
source : hemerobia_250m.tif
names : hemerobia_250m
values : 0, 18 (min, max)Para aquellos que no han experimentado con lenguajes de programación para manejo y análisis de datos, acá están pasando varias cosas. Repasamos algunas de ellas.
Primero que nada, un elemento fundamental que debemos mencionar es el de una función. Una función recibe argumentos y lleva a cabo una cierta tarea (aunque suene un poco raro también puede recibir ningún argumento y llevar a cabo una tarea). Las funciones siempre tienen un nombre y los argumentos que reciben se colocan dentro de paréntesis.
Show code
knitr::include_graphics("3_funciones.png")
Por ejemplo la función library() lleva a cabo la tarea de cargar un determinado paquete de R. Un argumento que DEBE recibir es el nombre del paquete a cargar. La función raster carga un raster en el espacio de trabajo de R (en la memoria RAM) y un argumento que DEBE recibir es la ruta en el disco duro del raster que se quiere cargar.
Cuando una función carga algo en memoria, esto se debe asignar a un objeto. Es decir que se debe de elegir un “nombre” con el cuál referirse a lo que se está cargando. Se puede elegir cualquier nombre pero se recomienda usar unos juiciosos para recordar de qué se tratan. Para asignar en R comúnmente se usa una flechita pero también puede usarse el símbolo de igual como en otros lenguajes de programación.
Show code
knitr::include_graphics("4_asigobjeto.png")
Hemos llamado ‘raster_evidencia’ al que acabamos de cargar, con este objeto podemos ver una versión cruda del mismo dentro de R.
Show code
plot(raster_evidencia)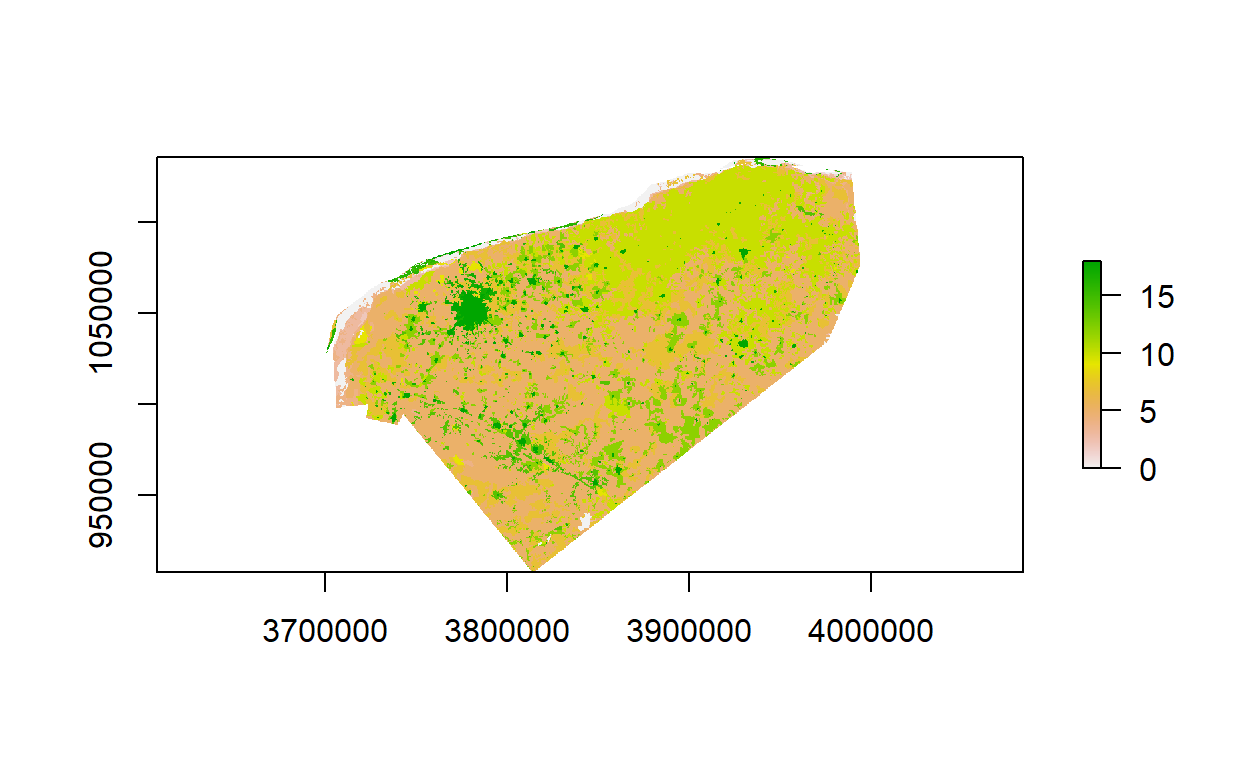
Ahora bien, un raster es una estructura que puede resultar muy útil para ciertos propósitos, pero para otros no tanto. Por ejemplo para llevar a cabo un proceso de análisis exploratorio de datos, el formato más común es el de una tabla de datos. De hecho R tiene un estándar de datos ampliamente aceptado llamado tidy data donde se analiza y describe cómo deberían de ser las tablas de datos para análisis. Dejando eso de lado, generalmente existen funciones en R (y en los otros lenguajes) para pasar de un tipo de objeto (dato) a otro. Por ejemplo de un raster a una tabla de datos:
Show code
tabla_evidencia <- as.data.frame(rasterToPoints(raster_evidencia))
head(tabla_evidencia) x y hemerobia_250m
1 3939125 1135625 16
2 3939375 1135625 16
3 3939625 1135625 16
4 3939875 1135625 16
5 3940125 1135625 16
6 3940375 1135625 16Acá cada fila es una observación (un píxel) y cada columna una variable coordenada x, coordenada y, el valor de hemerobia del píxel.
Show code
library("ggplot2")
ggplot(tabla_evidencia, aes(hemerobia_250m, fill = cut(hemerobia_250m, 11))) +
geom_histogram(show.legend = FALSE) +
scale_fill_brewer(palette="Greens")
Ejercicio 2: cambiar los colores de las barras del histograma para que tengan secuencia de semáforo y que verde sea lo mejor conservado y rojo lo peor.
Para nuestros propósitos conviene generar una tabla en formato tidy data que contenga cada raster que tenemos, el que acabamos de cargar (la respuesta) y los que corresponden a las variables explicativas.
Se debe tener en mente que todas las funciones que existen en R han sido escritas por alguien. Así que estamos en la posibilidad de escribir nuestra propia función para lograr una tarea que nos sea útil.
Escribir una función nueva en R es relativamente sencillo, prácticamente basta con darle un nombre, enlistar qué parámetros recibe, y qué hace la función con estos. Por ejemplo podemos escribir la función “elevar al cuadrado” que toma un número y lo multiplica por sí mismo.
Show code
elevar_al_cuadrado <- function(numero){
cuadrado <- numero*numero
return(cuadrado)
}Ya que la función está definida y la hemos corrido, está cargada en el espacio de trabajo y podemos usarla.
Show code
elevar_al_cuadrado(123)[1] 15129Ahora debemos pensar qué requerimos para generar la tabla de datos antes mencionada, como todo en la vida hay varias maneras de resolver esto. Una posibilidad es generar una lista de los rasters, leerlos uno por uno para luego agregarlos a un raster multi-capa o multi-banda y convertir este último en una tabla. Ahora bien, el único paso algo complicado podría ser leer los rasters uno por uno, puesto que debemos de escribir un pedazo de código que itere sobre la lista de rasters. Hagamos esto paso por paso. Primero generemos una lista de los rasters (.tif) en una ruta de interés.
Usaremos primero una función del paquete ‘tools’ para enlistar todos los archivos en una cierta ruta que tengan una extensión (.tif).
Show code
library("tools")
# Lista de los rasters considerados variables explicativas.
ruta_indep = list_files_with_exts("../../../data/indep_vars",
exts = "tif")
ruta_indep [1] "../../../data/indep_vars/AlturaFusteLimpio_desvest_250m.tif"
[2] "../../../data/indep_vars/AlturaFusteLimpio_media_250m.tif"
[3] "../../../data/indep_vars/AlturaTotal_desvest_250m.tif"
[4] "../../../data/indep_vars/AlturaTotal_media_250m.tif"
[5] "../../../data/indep_vars/DiametroCopa_desvest_250m.tif"
[6] "../../../data/indep_vars/DiametroCopa_media_250m.tif"
[7] "../../../data/indep_vars/DiametroNormal_desvest_250m.tif"
[8] "../../../data/indep_vars/DiametroNormal_media_250m.tif"
[9] "../../../data/indep_vars/hemerobia_250m.tif"
[10] "../../../data/indep_vars/net_photo_mean.tif"
[11] "../../../data/indep_vars/net_photo_mean_lluvias.tif"
[12] "../../../data/indep_vars/net_photo_mean_secas.tif"
[13] "../../../data/indep_vars/net_photo_sd.tif"
[14] "../../../data/indep_vars/presenciaArbolesMuertos_250m.tif"
[15] "../../../data/indep_vars/presenciaInsectos_250m.tif"
[16] "../../../data/indep_vars/propor_bosque.tif"
[17] "../../../data/indep_vars/propor_pastizaloagricultura.tif"
[18] "../../../data/indep_vars/propor_selva.tif"
[19] "../../../data/indep_vars/propor_suelodesnudo.tif"
[20] "../../../data/indep_vars/propor_urbano.tif"
[21] "../../../data/indep_vars/srtm90m_mean250m.tif"
[22] "../../../data/indep_vars/srtm90m_range250m.tif"
[23] "../../../data/indep_vars/zvh_31_lcc_h.tif" Hay muchos tipos de objetos en R (y en todos los lenguajes de programación). Listas, arreglos, matrices, data.frames.
Hay distintas maneras de “recorrer” cada uno de estos objetos pero ver esto a profundidad escapa el alcance de esta sesión. Vamos a ver cómo recorrer una lista. Estas son estructuras lineales, esto es contienen objetos (¡DE CUALQUIER TIPO!) en una única dimensión y estos se pueden seleccionar dando la posición que ocupan en la lista. Como ejemplo la lista de las rutas a rasters es una con longitud 22.
De aquí que podamos, por ejemplo, elegir la ruta del décimo raster.
Show code
ruta_indep[10][1] "../../../data/indep_vars/net_photo_mean.tif"O incluso elegir sólo del 10 al 15.
Show code
ruta_indep[10:15][1] "../../../data/indep_vars/net_photo_mean.tif"
[2] "../../../data/indep_vars/net_photo_mean_lluvias.tif"
[3] "../../../data/indep_vars/net_photo_mean_secas.tif"
[4] "../../../data/indep_vars/net_photo_sd.tif"
[5] "../../../data/indep_vars/presenciaArbolesMuertos_250m.tif"
[6] "../../../data/indep_vars/presenciaInsectos_250m.tif" Lo que haremos con esto es leer los rasters uno por uno utilizando un bucle. Los bucles (for loops) son de los paradigmas de iteración más comunes y viejos que hay. De nuevo hay muchas maneras de resolver esto. Si bien no es de las maneras más elegantes de lograr esto, es de utilidad puesto que siempre será posible utilizarlo, en cualquier lenguaje de programación, por lo universal que es.
Primero un bucle sencillo. Le diremos a la computadora, quiero que cuentes del 1 al 10 y en cada número digas la palabra ‘número’:
Show code
for (i in 1:10){ # Esto se lee para i que tomará los valores 1,2,3,...,10
print("numero") # Despliega el texto numero
}[1] "numero"
[1] "numero"
[1] "numero"
[1] "numero"
[1] "numero"
[1] "numero"
[1] "numero"
[1] "numero"
[1] "numero"
[1] "numero"Pero también le podríamos decir, despliega el número en el que vas:
Show code
for (i in 1:10){ # Esto se lee para i que tomará los valores 1,2,3,...,10
print(i) # Despliega el número en el que vas
}[1] 1
[1] 2
[1] 3
[1] 4
[1] 5
[1] 6
[1] 7
[1] 8
[1] 9
[1] 10Ejercicio 3: escribir un bucle que lea toda nuestra lista de rasters, uno por uno.
Juntando todo lo anterior podemos escribir una función que nos permita leer todos los rasters y luego con esto generar una tabla:
Show code
rutasAMulti = function(dep_path,
indep_paths){
bnbrik = brick()
bnbrik = addLayer(bnbrik,raster(dep_path))
for (i in 1:length(indep_paths)){
bnbrik = addLayer(bnbrik,raster(indep_paths[i]))
}
return(bnbrik)
}
# Hemerobia etá también en ruta_indep, así que lo elimino para no duplicar la capa
ruta_indep <- ruta_indep[!grepl("hemerobia", ruta_indep)]
raster_multi <- rutasAMulti("../../../data/delta_vp/hemerobia_250m.tif", ruta_indep)
tabla_multi <- as.data.frame(rasterToPoints(raster_multi))
head(tabla_multi) x y hemerobia_250m AlturaFusteLimpio_desvest_250m
1 3939125 1135625 16 0.00000000
2 3939375 1135625 16 0.54562950
3 3939625 1135625 16 0.02781332
4 3939875 1135625 16 0.02781332
5 3940125 1135625 16 0.02781332
6 3940375 1135625 16 0.02781332
AlturaFusteLimpio_media_250m AlturaTotal_desvest_250m
1 0.00000000 0.000000000
2 1.16930819 0.693956196
3 0.03184322 0.008685708
4 0.03184322 0.008685708
5 0.03184322 0.008685708
6 0.03184322 0.008685708
AlturaTotal_media_250m DiametroCopa_desvest_250m
1 0.0000000 0.02296904
2 4.6368446 0.17380011
3 0.0426484 0.07168859
4 0.0426484 0.07168859
5 0.0426484 0.07168859
6 0.0426484 0.07168859
DiametroCopa_media_250m DiametroNormal_desvest_250m
1 0.02391556 0.00000000
2 0.19083574 0.78119290
3 0.01392496 0.03274944
4 0.01392496 0.03274944
5 0.01392496 0.03274944
6 0.01392496 0.03274944
DiametroNormal_media_250m net_photo_mean net_photo_mean_lluvias
1 0.00000000 0 0
2 1.10098600 0 0
3 0.07778671 0 0
4 0.07778671 0 0
5 0.07778671 0 0
6 0.07778671 0 0
net_photo_mean_secas net_photo_sd presenciaArbolesMuertos_250m
1 0 0 NA
2 0 0 NA
3 0 0 NA
4 0 0 NA
5 0 0 NA
6 0 0 NA
presenciaInsectos_250m propor_bosque propor_pastizaloagricultura
1 NA 0 0
2 NA 0 0
3 NA 0 0
4 NA 0 0
5 NA 0 0
6 NA 0 0
propor_selva propor_suelodesnudo propor_urbano srtm90m_mean250m
1 0 0 2.469136 2.0
2 0 0 0.000000 3.5
3 0 0 0.000000 NA
4 0 0 2.469136 NA
5 0 0 2.222222 NA
6 0 0 0.000000 NA
srtm90m_range250m zvh_31_lcc_h
1 0 15
2 1 15
3 NA 15
4 NA 15
5 NA 15
6 NA 15Ahora podemos ajustar un primer modelo entre las variables explicativas y nuestra respuesta. Ajustaremos un modelo lineal. Por un momento dejaremos de lado la variable “zonas de vida de holdridge” [22] y también excluiremos las columnas-coordenadas.
Show code
datos_modelo <- tabla_multi[,3:24] # Quitar coordenadas y ZVH.
datos_modelo <- datos_modelo[complete.cases(datos_modelo),] # Quitar casos con valores faltantes.
modelo_lineal <- lm(hemerobia_250m~., data = datos_modelo) # Ajuste modelo.
# La fórmula variable~. significa variable explicada por "todo lo demás".
summary(modelo_lineal)
Call:
lm(formula = hemerobia_250m ~ ., data = datos_modelo)
Residuals:
Min 1Q Median 3Q Max
-17.5742 -1.5425 -0.6471 1.1071 12.5245
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.9607597 0.0747690 52.973 < 2e-16
AlturaFusteLimpio_desvest_250m -0.6420698 0.0331591 -19.363 < 2e-16
AlturaFusteLimpio_media_250m -0.2972919 0.0129057 -23.036 < 2e-16
AlturaTotal_desvest_250m 1.5600010 0.0235607 66.212 < 2e-16
AlturaTotal_media_250m 0.3146922 0.0079551 39.559 < 2e-16
DiametroCopa_desvest_250m 1.7902153 0.0461978 38.751 < 2e-16
DiametroCopa_media_250m -0.1151313 0.0156566 -7.354 1.93e-13
DiametroNormal_desvest_250m -0.1315326 0.0052809 -24.907 < 2e-16
DiametroNormal_media_250m -0.1055519 0.0040341 -26.165 < 2e-16
net_photo_mean -0.0457011 0.0022202 -20.584 < 2e-16
net_photo_mean_lluvias 0.0291710 0.0010958 26.621 < 2e-16
net_photo_mean_secas 0.0115336 0.0011334 10.176 < 2e-16
net_photo_sd -0.0029836 0.0002019 -14.778 < 2e-16
presenciaArbolesMuertos_250m 4.0028680 0.0393549 101.712 < 2e-16
presenciaInsectos_250m -1.7508169 0.0332284 -52.690 < 2e-16
propor_bosque 1.1448459 1.5805864 0.724 0.469
propor_pastizaloagricultura 0.0462580 0.0006884 67.198 < 2e-16
propor_selva 0.0124566 0.0006940 17.949 < 2e-16
propor_suelodesnudo 0.0299204 0.0011090 26.980 < 2e-16
propor_urbano 0.1184421 0.0006473 182.983 < 2e-16
srtm90m_mean250m -0.0008771 0.0001808 -4.851 1.23e-06
srtm90m_range250m -0.0063388 0.0010698 -5.925 3.12e-09
(Intercept) ***
AlturaFusteLimpio_desvest_250m ***
AlturaFusteLimpio_media_250m ***
AlturaTotal_desvest_250m ***
AlturaTotal_media_250m ***
DiametroCopa_desvest_250m ***
DiametroCopa_media_250m ***
DiametroNormal_desvest_250m ***
DiametroNormal_media_250m ***
net_photo_mean ***
net_photo_mean_lluvias ***
net_photo_mean_secas ***
net_photo_sd ***
presenciaArbolesMuertos_250m ***
presenciaInsectos_250m ***
propor_bosque
propor_pastizaloagricultura ***
propor_selva ***
propor_suelodesnudo ***
propor_urbano ***
srtm90m_mean250m ***
srtm90m_range250m ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.625 on 593781 degrees of freedom
Multiple R-squared: 0.3946, Adjusted R-squared: 0.3946
F-statistic: 1.843e+04 on 21 and 593781 DF, p-value: < 2.2e-16Aunque no es un modelo muy bueno por múltiples razones, ya nos permite contestar algunas preguntas. Por ejemplo qué pasa si ponemos un centro urbano en algún lugar?
Ejercicio 4: encontrar una observación bien conservada de la tabla de datos y utilizar el modelo para estimar qué pasaría si aumenta la cantidad de clase urbana ahí. Ayuda: investigar cómo se utiliza la función predict. Las tablas se pueden recorrer igual que las listas pero naturalmente tienen dos dimensiones en vez de solo una tabla[1:2,10:22] e incluso con condiciones, e.g. tabla[tabla$hemerobia_250m == 0,]. El símbolo de pesos se refiere a elegir una columna.
¿Por qué Redes Bayesianas?
Show code
knitr::include_graphics("6_bn4.png")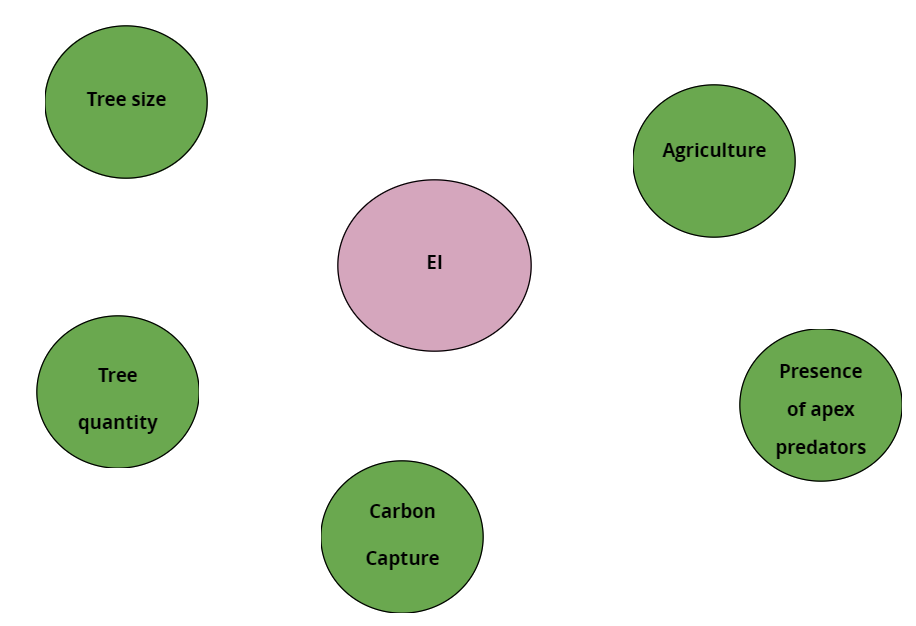
Figure 1: Variables related in someway to EI.
Qué influencia tienen estas variables explicativas sobre lo que llamamos IE?
Nuestra regresión lineal diría, por ejemplo, que IE es una suma ponderada de las variables explicativas.
Show code
knitr::include_graphics("7_linear.png")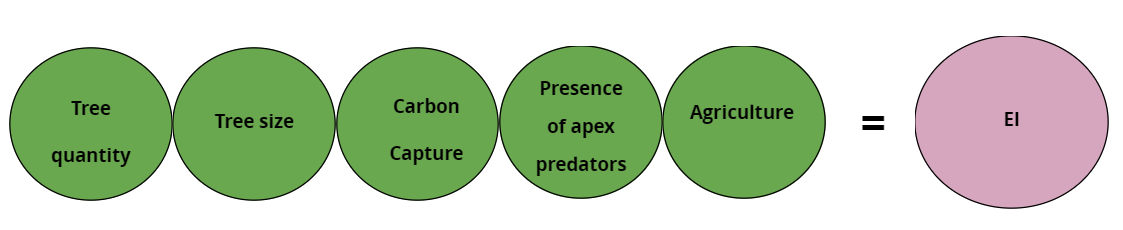
Figure 2: Modelo lineal.
Pero, por ejemplo, no estamos también interesados en cómo la presencia de depredadores tope influencian la captura de carbono?
Show code
knitr::include_graphics("8_linear2.png")
Figure 3: Qué hay de las relaciones entre variables explicativas?.
Las Redes Bayesianas nos dejan proponer estructuras entrecruzadas de correlación entre variables.
Show code
knitr::include_graphics("9_bnie.png")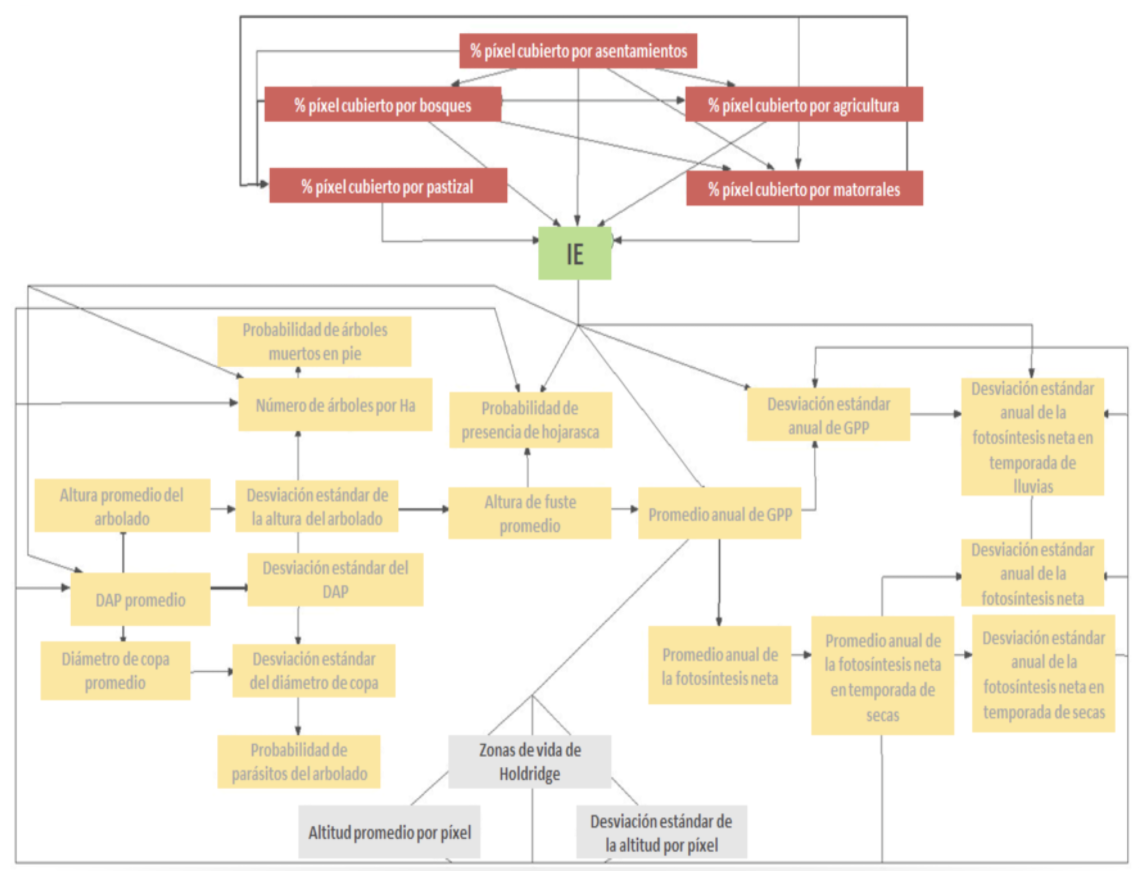
Figure 4: Modelo actual de EI.
Un comentario sobre armonización de datos
Finalmente se debe mencionar que lo trabajado anteriormente asume que los datos de entrada (los rasters) se encuentran armonizados, esto es que mantienen la misma resolución, proyección, extent, etc…
Esto puede requerir procesos más o menos complejos, como reproyectar, agregar o desagregar píxeles, rasterizar archivos vectoriales, etc… pero todo se puede hacer con lo antes expuesto y con las funciones contenidas en los paquetes de GIS en R o en cualquier otro lenguaje como python. Por supuesto es buena idea tener un raster molde el cuál utilizar como referente.